I'll be up all night with this little minion. The other cat is wearing a tin foil hat look at this new fashionable attire.
There is a lot of benefit to be had though. It will likely suck at first and I think the tendency for outsourcing this kind of thing is idiotic. The gov needs to be the AI administrator AND the company because AI is extremely privacy invasive and should never be commercialized in any capacity with kids. I don't support even the school having full access to a child's prompting. I say this because I have intimate knowledge of what kind of information can be accessed using this and how invasive it is. I only run my own open source models on my own offline hardware. The only persons within a school with full access to a child's prompting should be someone bound to confidentiality and a Hippocratic oath like a licensed psychiatrist with no obligations or bias towards the school's petty interests.
The education system is largely antiquated presently. I'm all for supporting my community with living wage jobs. Our reductionist culture is a big part of why we are falling apart. When we are presented with efficiency improvements, we are too stupid to adapt, and too stupid to use them as a resource. We flush out that newly created value instead of investing it immediately within ourselves.
The world has changed from an era when a traditional teacher is relevant. Audio visual information is our primary form of communication. With readily available video, it is criminal to continue live lecturing and presentation of static information. There is no chance that the live presentation of information is anywhere near the quality of a polished and edited video. There is very little chance that any given lecturer is truly the best at presenting such information. Such a statement glosses over the fact that there are an enormous range of personalities and functional thought processes. It is extremely unlikely that any given teacher connects well with each individual student. We have had readily available video communication for over a decade. Some university professors readily use the medium and offer class time as more of a workshop or lab environment. Most primary schools lack this kind of adoption of technology, complexity, and efficiency to keep up with the changing world. In truth, we lack the requirement for a teacher to be a life long learner too.
I expect much the same Luddism with AI. With teaching kids, this is pushing AI to the point where it needs serious supervision to be effective. Maintaining a child's autonomy and right to privacy is absolutely critical for the future of society as a whole. However, the ability for AI to adapt to any functional thought and help with individualized problem solving is something that no teacher is capable of with more than one student at a time.
Most of us had to persist through our frustration in order to learn. AI can directly and individually address that frustration and find a solution. It is not always correct, but it is in the same realm of accuracy as an above average teacher. Maybe you too were aware of just how many teachers did not even know the subjects they were tasked with teaching in primary school, I certainly was.
Artist was really dialed in to their audience. Don't hate. The streamer service is a bot. The ad system is a bot. The payment system is a bot. This man did to others as they did to him.
Have a conversation with a successful stripper about human psychology some time; about reading people, desire, and something along the lines of platonic sophism. Some have a lot more brains than stereotypes might assume. I think of them more like honest politicians in a sense.
It might have happened to me too earlier using alexandrite UI on a world account. I can't be sure because I'm a zombie today with next to no sleep, however I replied to someone and it popped up on the wrong poster like 6 hours ago. This is highly unusual for me, even when extremely sleep deprived. I edited, and pasted the message appropriately. I have not seen the problem occur again since. I assumed it must have been me, but after seeing this post, I would say both are equally plausible; it was very out of character for me.
Not really. There are very few lobbyists for a non dystopian future. The battle for the right to own your tools is the absolute fulcrum of the future and the next several centuries. The loss of ownership rights is the largest sociopolitical issue and regression of the past millennia. The atrocity of feudalism was already hashed out as a terrible and failed social structure. Allowing it to reemerge will have extreme long term impacts
The way people fail to see and understand this issue speaks to the potential force needed to shift the trend and trajectory. All it takes are a few influential and connected people working to shift the political conversation and momentum in the opposite direction to alter the course of the future. Funding a few individuals to speak up for us could make an enormous impact. Ownership IS citizenship; IS democracy. Trusting others while renting tools and property IS feudalism. It is a path to slavery in all but name. It happened before, and is always the inevitable outcome of this situation. Putting up any fight against the lackadaisical complacency of our present culture absolutely has the potential to impact the future in a substantial way.
Call up Louis Rossmann and have a talk about how you can help with democracy to stop the present dystopian neo feudal regression in the world. Long term, you could impact the trajectory of the next few centuries in substantial ways and lessen the coming dark age.
Barbarian human practice for pet population control. I feel so guilty about the ethics
Cloak of invisibility; close, but not too close; present but never seen. At that moment, The Chair (string mousey) PRO hunter's blind
She is surprisingly compliant.
I'll be up all night with this little minion. The other cat is wearing a tin foil hat look at this new fashionable attire.
Which ones kick my ass in math?
Major Taylor was Black and one of, if not the first, true international sports celebrities. https://en.wikipedia.org/wiki/Major_Taylor
Just to contrast:
From 1893 to 1900 Benz sold the four wheel, two seat Victoria,[19] a two-passenger automobile with a 2.2 kW (3.0 hp) engine, which could reach the top speed of 18 km/h (11 mph) and had a pivotal front axle operated by a roller-chained tiller for steering. The model was successful with 85 units sold in 1893, and was produced in a four-seated version with face-to-face seat benches called the "Vis-à-Vis".
From 1894 to 1902, Benz produced over 1,200 of what some consider the first mass-produced car, the Velocipede, later known as the Benz Velo.[20] The early Velo had a 1L 1.5-metric-horsepower (1.5 hp; 1.1 kW) engine, and later a 3-metric-horsepower (3 hp; 2 kW) engine. giving a top speed of 19 km/h (12 mph).
The Velo participated in the world's first automobile race, the 1894 Paris to Rouen, where Émile Roger finished 14th, after covering the 126 km (78 mi) in 10 hours 01-minute at an average speed of 12.7 km/h (7.9 mph).
In 1895, Benz designed the first truck with an internal combustion engine in history. Benz also built the first motor buses in history in 1895, for the Netphener bus company.[21][22][23]
In 1896, Benz was granted a patent for his design of the first flat engine. It had horizontally opposed pistons, a design in which the corresponding pistons reach top dead centre simultaneously, thus balancing each other with respect to momentum. Many flat engines, particularly those with four or fewer cylinders, are arranged as "boxer engines", boxermotor in German, and also are known as "horizontally opposed engines".

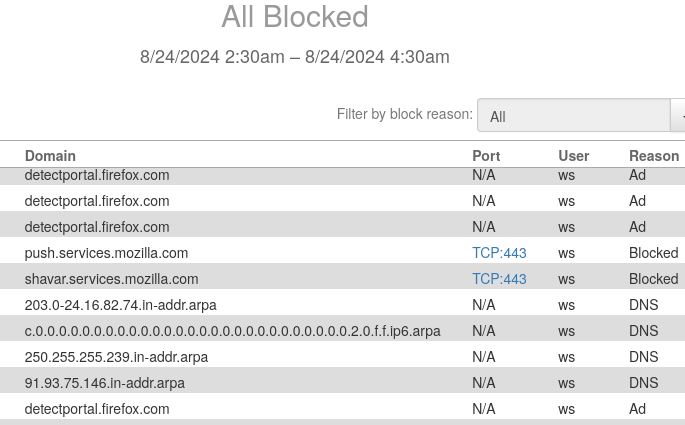
I just went to use nvcc for the first time and this nonsense hit my firewall. Make won't compile but it has to do with my unwillingness to use the proprietary toolkit. This network activity only happened once on startup.


::: spoiler I was overweight in my late teens and by my mid twenties I was in really bad shape at 340lbs at my worst. I was in a Target with serious chest pains at one point. I'm not a whiner type and have a significantly above average pain threshold, but I wondered if I would even make it back to my car and get home that day. That was in '08. By '09 I had to move back in with family and started riding a bicycle everywhere. I had tried running and rowing when I was younger, and when I was overweight, some of that was from semi regular gym visits and weight lifting. Nothing ever really stuck like a real lifestyle though. They were always things I made myself add to my routine. I tend to overheat from aerobic exercise. Overheating in this context is really hard to define in a relatable way because it is such an intimate concept to my self awareness. Mainly my head tends to get much hotter than the rest of my body in such a way that I am extremely uncomfortable. I can easily put up with that unpleasantness. If I had never gotten into hardcore cycling, I wouldn't have known this unpleasant overheating was even a thing separate from exercise itself.
I come from a background of hot rodding cars. Internally, I always had this notion that I was failing at life if I could paint cars, airbrush graphics, build motors, and fabricate at such a high level, but couldn't do the same with myself and my body as the driver. This curiosity is a major driver in why I rode so persistently through the first couple of months to get past the worst discomfort and made it to a routine. The part that made it different from all aerobic efforts previously was the airflow on a bike, it's massive. The cooling effect got me. I resisted the clothing at first, like everyone does, but after realizing its utility and purpose, it unlocked the cooling effect even more. I made it to under 190 lbs, worked in a bike shop, and raced. It was really the best I had ever felt in my life by a long shot. The lack of impact with cycling also has a fantastic effect on loosening up your body and improving aches and pains. I had felt like I was aging in addition to chest pains and other problems when I was 340lbs but that all went away with riding.
I was super unlucky and was partially disabled by a driver in '14. I had a bunch of broken bones and barely survived. I now walk around slowly, and can't hold posture for very long at all. Still, I can ride. It is nothing like it was in the past. I can only do ~30 miles in a day regularly when I could pull a 100 mile day weekly in the past, and have ridden 200+ miles in a day before. At the present, it does not feel like I can or should be riding, but so long as I maintain my routine that includes nearly daily cycling, I am empirically in my best shape in terms of the least aches, pains, and problems even with severe chronic problems. There is no chance I would be able to establish such a cycling routine from my current state, but I came into my condition as an amateur racer, so I had that advantage and never lost my race legs. If at all possible, consider road cycling. Get a proper bike and get someone to fit you on the bike (adjust and swap required components to fine tune your anatomy to the bike) because with road, the little details are super important or you'll cause issues from that level of repetitive motion. There are a lot of disabled people on bikes too. In a shop, I was the Buyer and often helped people with unique needs. It may not be right for you, but is maybe something to think about. Cycling changes more than your physique, it impacts your physical and mental health in profound ways. Cycling really is a lifestyle. On a bike your both free and anonymous for the most part.