this post was submitted on 25 Jun 2025
776 points (99.0% liked)
politics
24378 readers
6189 users here now
Welcome to the discussion of US Politics!
Rules:
- Post only links to articles, Title must fairly describe link contents. If your title differs from the site’s, it should only be to add context or be more descriptive. Do not post entire articles in the body or in the comments.
Links must be to the original source, not an aggregator like Google Amp, MSN, or Yahoo.
Example:
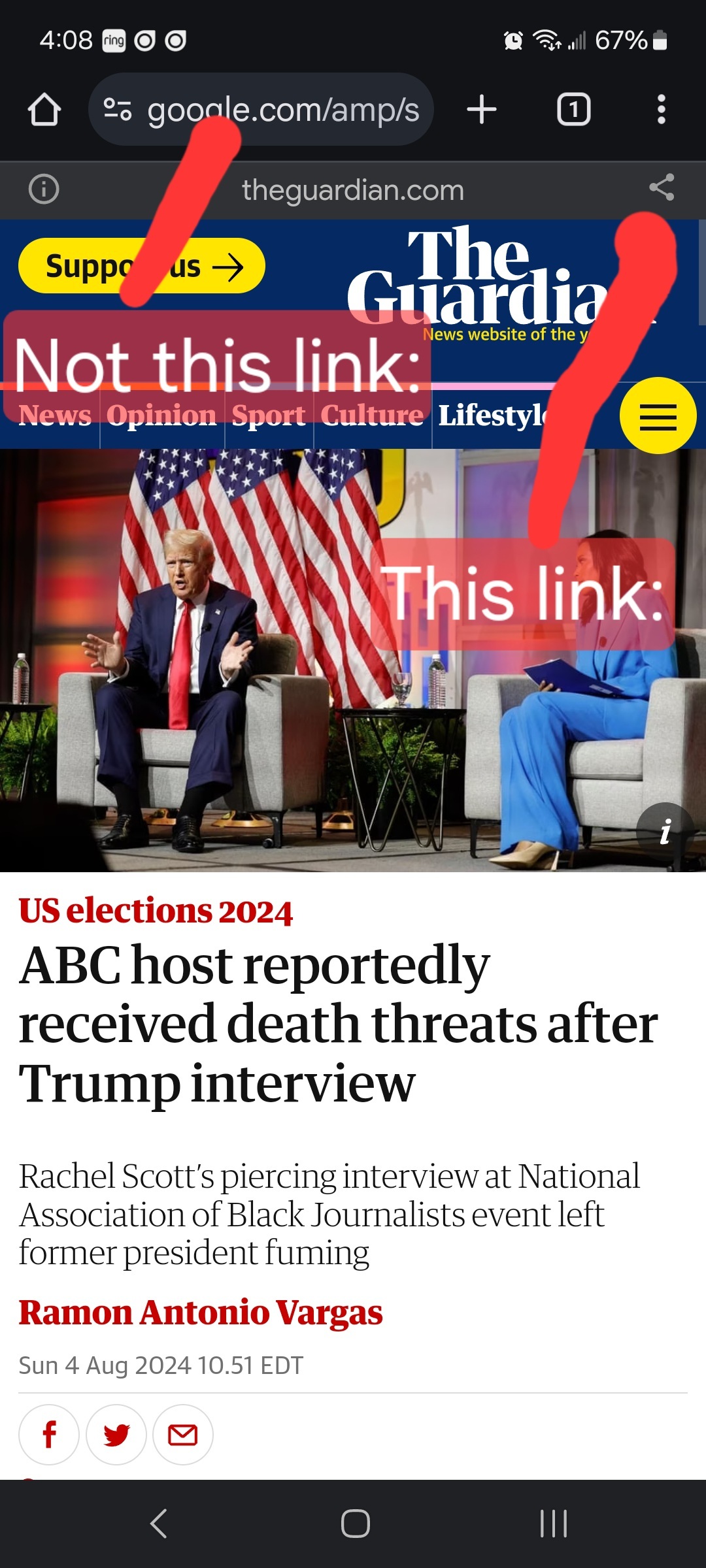
- Articles must be relevant to politics. Links must be to quality and original content. Articles should be worth reading. Clickbait, stub articles, and rehosted or stolen content are not allowed. Check your source for Reliability and Bias here.
- Be civil, No violations of TOS.
It’s OK to say the subject of an article is behaving like a (pejorative, pejorative). It’s NOT OK to say another USER is (pejorative). Strong language is fine, just not directed at other members. Engage in good-faith and with respect! This includes accusing another user of being a bot or paid actor. Trolling is uncivil and is grounds for removal and/or a community ban.
- No memes, trolling, or low-effort comments.
Reposts, misinformation, off-topic, trolling, or offensive. Similarly, if you see posts along these lines, do not engage. Report them, block them, and live a happier life than they do. We see too many slapfights that boil down to "Mom! He's bugging me!" and "I'm not touching you!" Going forward, slapfights will result in removed comments and temp bans to cool off.
- Vote based on comment quality, not agreement. This community aims to foster discussion; please reward people for putting effort into articulating their viewpoint, even if you disagree with it.
- No hate speech, slurs, celebrating death, advocating violence, or abusive language. This will result in a ban. Usernames containing racist, or inappropriate slurs will be banned without warning
We ask that the users report any comment or post that violate the rules, to use critical thinking when reading, posting or commenting. Users that post off-topic spam, advocate violence, have multiple comments or posts removed, weaponize reports or violate the code of conduct will be banned.
All posts and comments will be reviewed on a case-by-case basis. This means that some content that violates the rules may be allowed, while other content that does not violate the rules may be removed. The moderators retain the right to remove any content and ban users.
That's all the rules!
Civic Links
• Register To Vote
• Citizenship Resource Center
• Congressional Awards Program
• Federal Government Agencies
• Library of Congress Legislative Resources
• The White House
• U.S. House of Representatives
• U.S. Senate
Partnered Communities:
• News
• World News
• Business News
• Political Discussion
• Ask Politics
• Military News
• Global Politics
• Moderate Politics
• Progressive Politics
• UK Politics
• Canadian Politics
• Australian Politics
• New Zealand Politics
founded 2 years ago
MODERATORS
Like, a lot? Probably more or less same as you, surely
Just being able to move, own stuff, save my work for the future and be free to speak my mind without coercion are huge boons
And to do so efficiently without so much physical work or being afraid for my life every second is a bless
But my freedom is not absolute, you surely understand