See the post on BlueSky: https://bsky.app/profile/provisionalidea.bsky.social/post/3lhujtm2qkc2i
According to many comments, the US government DOES use SQL, and Musk is not understanding much what's going on.
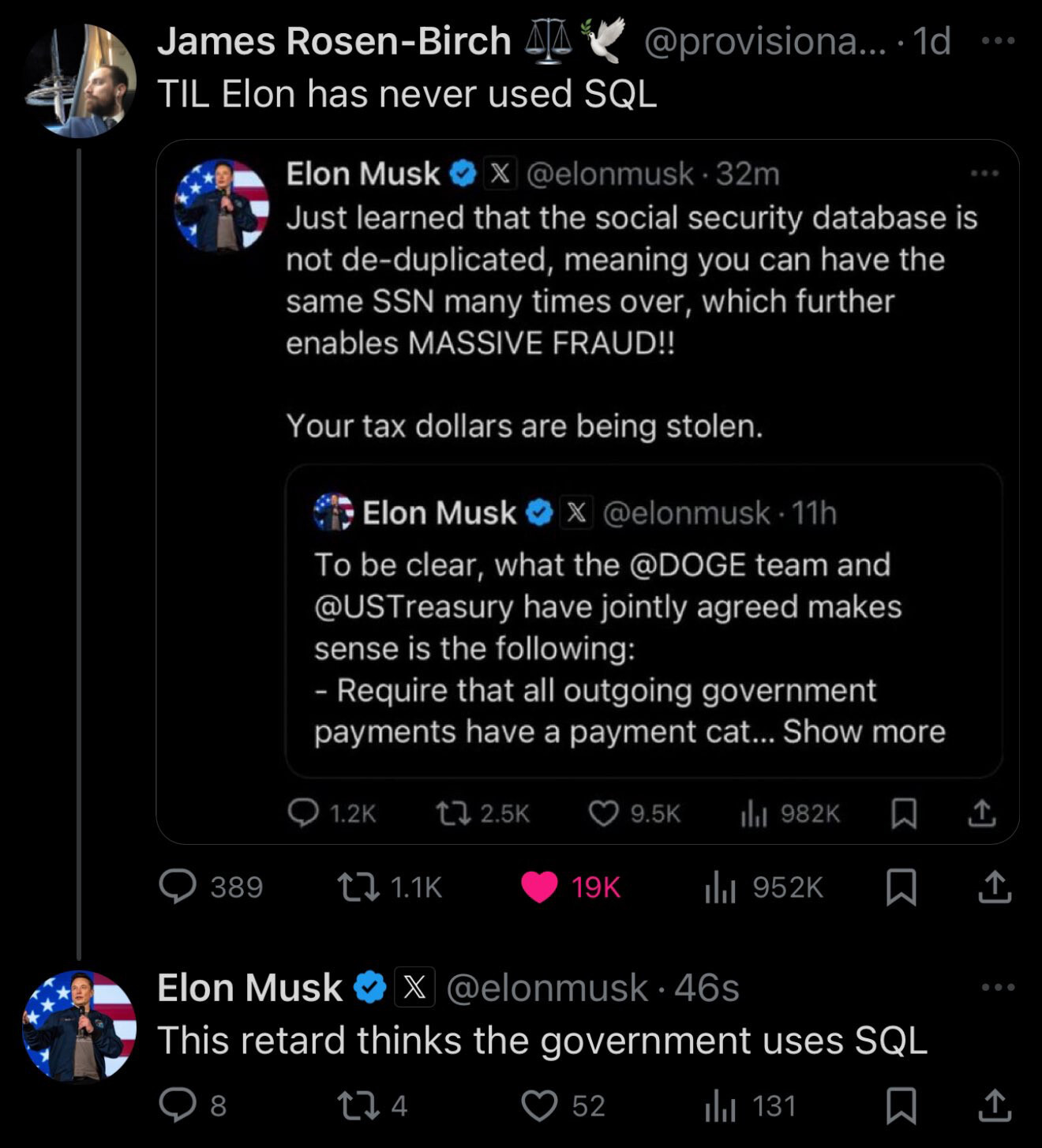
See the post on BlueSky: https://bsky.app/profile/provisionalidea.bsky.social/post/3lhujtm2qkc2i
According to many comments, the US government DOES use SQL, and Musk is not understanding much what's going on.
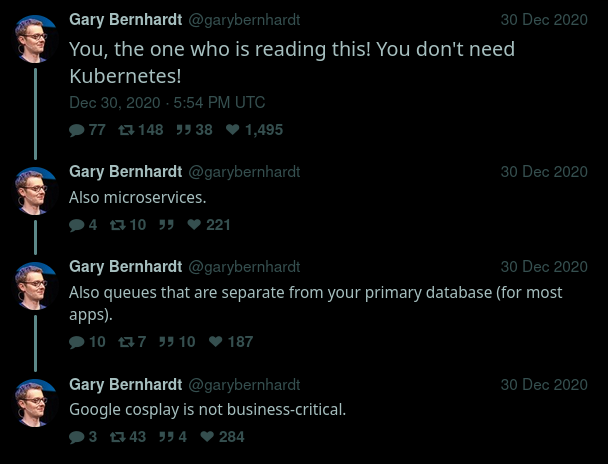
Transcription: a Twitter thread from Gary Bernhardt.
Source: https://twitter.com/garybernhardt/status/1344341213575483399