Make Vector Topographic Maps (Open Street Map, Maperitive, and Inkscape)
by Michael Altfield
This guide will show you how to generate vector-based topopgraphic maps, for printing very large & high-quality paper wall maps using inkscape. All of the tools used in this guide are free (as in beer).
 |
|---|
| How-to Guide to Making Vector Topo Maps with Maperitive and Inkscape |
Intro
I recently volunteered at a Biological Research Station located on the eastern slopes of the Andes mountains. If the skies were clear (which is almost never, as it's a cloud forest), you would have a great view overlooking the Amazon Rainforest below.
 |
|---|
| Yanayacu is in a cloud forest on the east slopes of the Andes mountains, just 30 km from the summit of the glacial-capped Antisana volcano (source) |
The field station was many years old with some permanent structures and a network of established trails that meandered towards the border of Antisana National Park -- a protected area rich with biodiversity that attracts biologists from around the world. At the top of the park is a glacial-capped volcano with a summit at 5,753 meters.
Surprisingly, though Estacion Biologicia Yanayacu was over 30 years old, nobody ever prepared a proper map of their trails. And certainly there was no high-resolution topographical map of the area to be found at the Station.
That was my task: to generate maps that we could bring to a local print shop to print-out huge 1-3 meter topographical maps.
And if you want to print massive posters that don't look terrible, you're going to be working with vector graphics. However, most of the tools that I found for browsing Open Street Map data that included contour lines couldn't export an SVG. And the tools I found that could export an SVG, couldn't export contour lines.
It took me several days to figure out how to render a topographical map and export it as an SVG. This article will explain how, so you can produce a vector-based topographical map in about half a day of work.
Assumptions
This guide was written in 2024, and it uses the following software and versions:
- Debian 12 (bookworm)
- OsmAnd~ v4.7.10
- JOSM v18646
- Maperitive v2.4.3
- Inkscape v1.2.2
The Tools
Unfortunately, there's no all-in-one app that will let you just load a slippy map, zoom-in, draw a box, and hit "export as SVG". We'll be using a few different tools to meet our needs.
 |
|---|
| OsmAnd |
OsmAnd
OsmAnd is a mobile app.
We'll be using OsmAnd to walk around on the trails and generate GPX files (which contain a set of GPS coordinates and some metadata). We'll use these coordinates to generate vector lines of a trail overlaying the topographic map.
If you just want a topographic map without trails (or your trails are already marked on OSM data), then you won't need this tool.
In this guide we'll be using OsmAnd, but you an also use other apps -- such as Organic Maps, Maps.me, or Gaia.
 |
|---|
| JOSM |
JOSM
JOSM is a java-based tool for editing Open Street Map data.
We'll be using JOSM to upload the paths of our trails (recorded GPX files from OsmAnd) and also to download additional data (rivers, national park boundary line, road to the trailhead, etc). We'll then be able to combine all of this data into a larger GPX file, which will eventually become vector lines overlaying the topographic map.
You can skip this if you just want contour lines without things like rivers, roads, trails, buildings, and park borders.
View Finder Panoramas
Have you ever wondered how you can zoom-in almost anywhere in the world and see contour lines? I always thought that this was the result of some herculean effort of surveyors scaling mountains and descending canyons the world-over. But, no -- it's a product of the US Space Shuttle program.
In the year 2000, an international program called SRTM (Shuttle Radar Topography Mission) was launched into space with the Endaevor Space Shuttle. It consisted of a special radar system tethered to the shuttle with a 60 meter mast as it orbited the earth.
 |
|---|
| This illustration shows the Space Shuttle Endeavour orbiting ~233 kilometers above Earth. The two anternae, one located in the Shuttle bay and the other located on a 60-meter mast, were able to penetrate clouds, obtaining 3-dimentional topographic images of the world's surface (source: NASA) |
When the shuttle returned to earth, the majority of our planet's contours were mapped. This data was placed on the public domain. Today, it is the main data source for elevation data in most maps.
While the data from SRTM was a huge boon to cartographers, it did have some gaps. Namely: elevation data was missing in very tall mountains and very low canyons. Subsequent work was done to fill-in these gaps. One particular source that ingested the SRTM data, completed its gaps, and made the results public is Jonathan de Ferranti's viewfinderpanoramas.org.
We will be downloading .hgt files from View Finder Panoramas in order to generate vector contour lines for our topographical map.
 |
|---|
| Maperitive |
Maperitive
Maperitive is a closed-source .NET-based mapping software (which runs fine in Linux with mono).
We'll be using Maperitive to tie together our GPX tracks, generate contour lines, generate hillshades, and export it all as a SVG.
 |
|---|
| Inkscape |
Inkscape
Inkscape is a cross-platform app for artists working with vector graphics.
We'll be using inkscape to make some final touches to our vector image, such as hiding some paths, changing their stroke color/shape/thickness, and adding/moving text labels. Finally, we'll use inkscape to export a gigantic, high-definition .png raster image (to send to the print shop).
Guide
To read the full guide on how to create vector-based maps, click here:
Example Maps
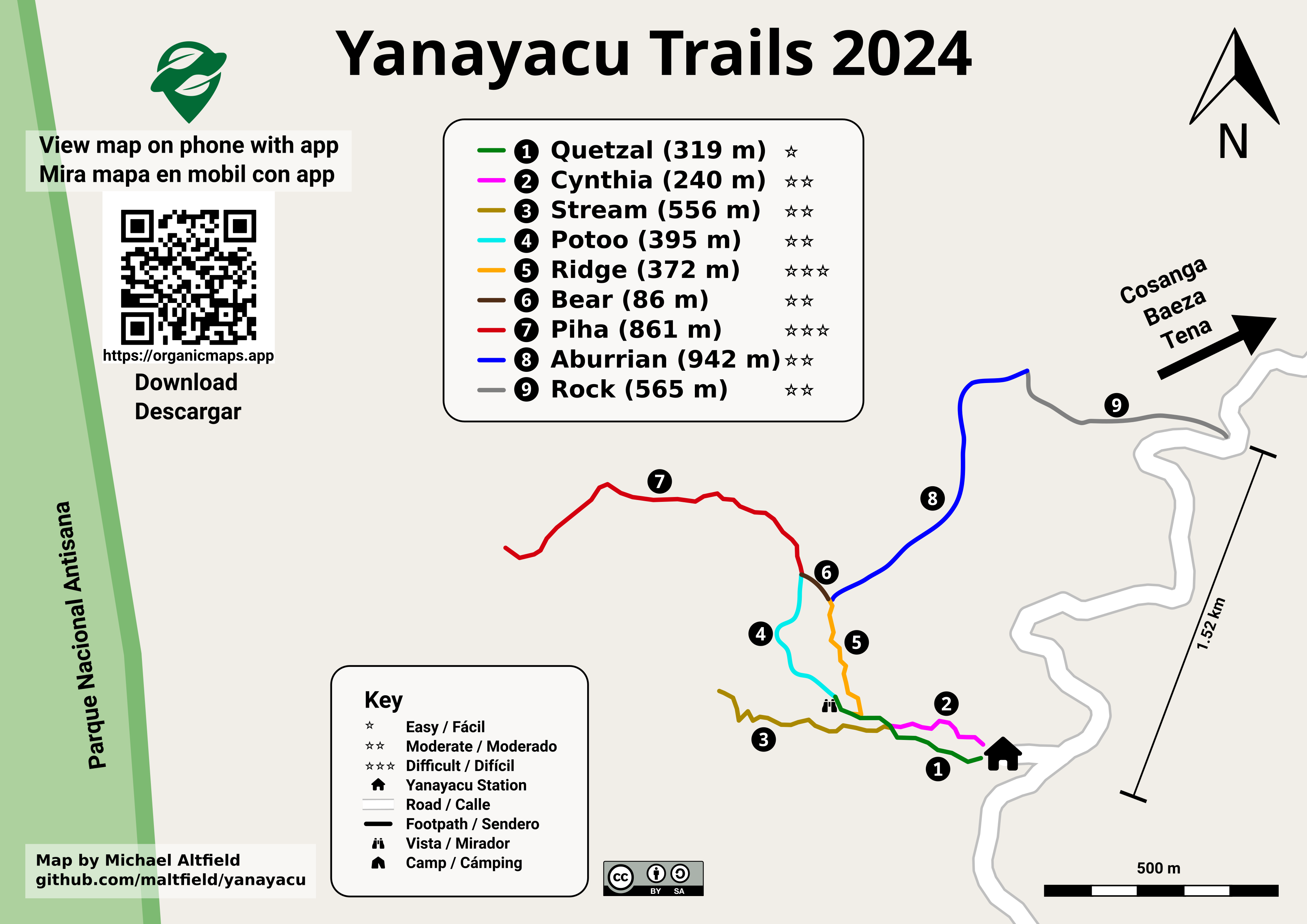
For example, here's the (A4-sized) topo map that I built for Yanayacu.
 |
|---|
| Final (raster) export, ready for sending to the print shop (source svg) |
Note that I changed the stroke and thickness of the National Park boundary to be large and green, I changed the path of the road (downloaded from OSM data in JOSM) to be thick and black, and I changed my GPX tracks (recorded in OsmAnd and merged with the OSM data in JOSM) to be thin, dashed, and red.
The source .svg file for the above image can be found here
I also used this method to generate a simplified "trail map" of Yanayacu (without contour lines). The workflow was similar, except I didn't generate contour nor hillshades layers in Maperitive before exporting as a .svg
 ) ) |
|---|
| Yanayacu Trail Guide (source svg) |
The source .svg file for the above image can be found here






![[BusKill] Our Dead Man Switch Magnetic USB Breakaway cables are NowAvailable in-person in Leipzig, Germany atProxyStore](https://www.buskill.in/wp-content/uploads/sites/8/leipzig-proxystore-featuredImage9.jpg)

_(39680659444).jpg){kind=link}
_Illustration.jpg){kind=link}
{kind=link}
{kind=link}