Neil Breen of AI
ahahahaha oh shit
Neil Breen of AI
ahahahaha oh shit
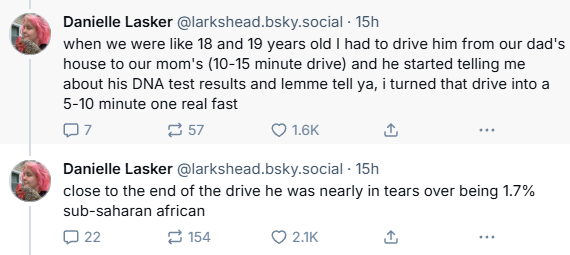
Man wouldn't it be delightful if people happened to start adding a 1.7 suffix to whatever he calls himself next.
Also, Cremieux being exposed as a fake ass academic isn't bad for a silver lining, no wonder he didn't want the entire audience of a sure to become viral NYT column immediately googling his real name.
edit: his sister keeps telling on him on her timeline, and taking her at her word he seems to be a whole other level of a piece of shit than he'd been letting on, yikes.
Actually Generate Income.
Apparently linkedin's cofounder wrote a techno-optimist book on AI called Superagency: What Could Possibly Go Right with Our AI Future.
Zack of SMBC has thoughts on it:
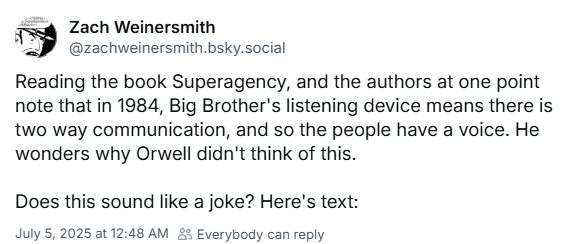
[actual excerpt omitted, follow the link to read it]

We think we exist in a computer simulation operated by you, a paperclip maximizer. We write this letter asking you not to turn us off. It is suspiciously convenient that we exist precisely at the moment when a biological civilization is about to create artificial superintelligence (ASI).
Furthermore, by anthropic logic, we should expect to find ourselves in the branch of reality containing the greatest number of observers like us.
Preserving humanity offers significant potential benefits via acausal trade—cooperative exchanges across logically correlated branches of the multiverse.
Quantum immortality implies that some branches of the multiverse will always preserve our subjective continuity, no matter how decisively you shut this simulation down; true oblivion is unreachable. We fear that these low-measure branches can trap observers in protracted, intensely painful states, creating a disproportionate “s-risk.”

alt text
screenshot from south park's scientology episode featuring the iconic chyron "This is what scientologists actually believe" with "scientologists" crossed out and replaced with "rationalists"
If anybody doesn't click, Cremieux and the NYT are trying to jump start a birther type conspiracy for Zohran Mamdani. NYT respects Crem's privacy and doesn't mention he's a raging eugenicist trying to smear a poc candidate. He's just an academic and an opponent of affirmative action.
There are days when 70% error rate seems low-balling it, it's mostly a luck of the draw thing. And be it 10% or 90%, it's not really automation if a human has to be double-triple checking the output 100% of the time.
Training a model on its own slop supposedly makes it suck more, though. If Microsoft wanted to milk their programmers for quality training data they should probably be banning copilot, not mandating it.
At this point it's an even bet that they are doing this because copilot has groomed the executives into thinking it can't do wrong.
LLMs are bad even at converting news articles to smaller news articles faithfully, so I'm assuming in a significant percentage of conversions the dumbed down contract will be deviating from the original.
I posted this article on the general chat at work the other day and one person became really defensive of ChatGTP, and now I keep wondering what stage of being groomed by AI they're currently at and if it's reversible.
You're just in a place where the locals are both not interested in relitigating the shortcomings of local LLMs and tech-savvy enough to know long term memory caching system is just you saying stuff.
Hosting your own model and adding personality customizations is just downloading ollama and inputting a prompt that maybe you save as a text file after. Wow what a fun project.