Meta has released and open-sourced Llama 3.1 in three different sizes: 8B, 70B, and 405B
This new Llama iteration and update brings state-of-the-art performance to open-source ecosystems.
If you've had a chance to use Llama 3.1 in any of its variants - let us know how you like it and what you're using it for in the comments below!
Llama 3.1 Megathread
For this release, we evaluated performance on over 150 benchmark datasets that span a wide range of languages. In addition, we performed extensive human evaluations that compare Llama 3.1 with competing models in real-world scenarios. Our experimental evaluation suggests that our flagship model is competitive with leading foundation models across a range of tasks, including GPT-4, GPT-4o, and Claude 3.5 Sonnet. Additionally, our smaller models are competitive with closed and open models that have a similar number of parameters.
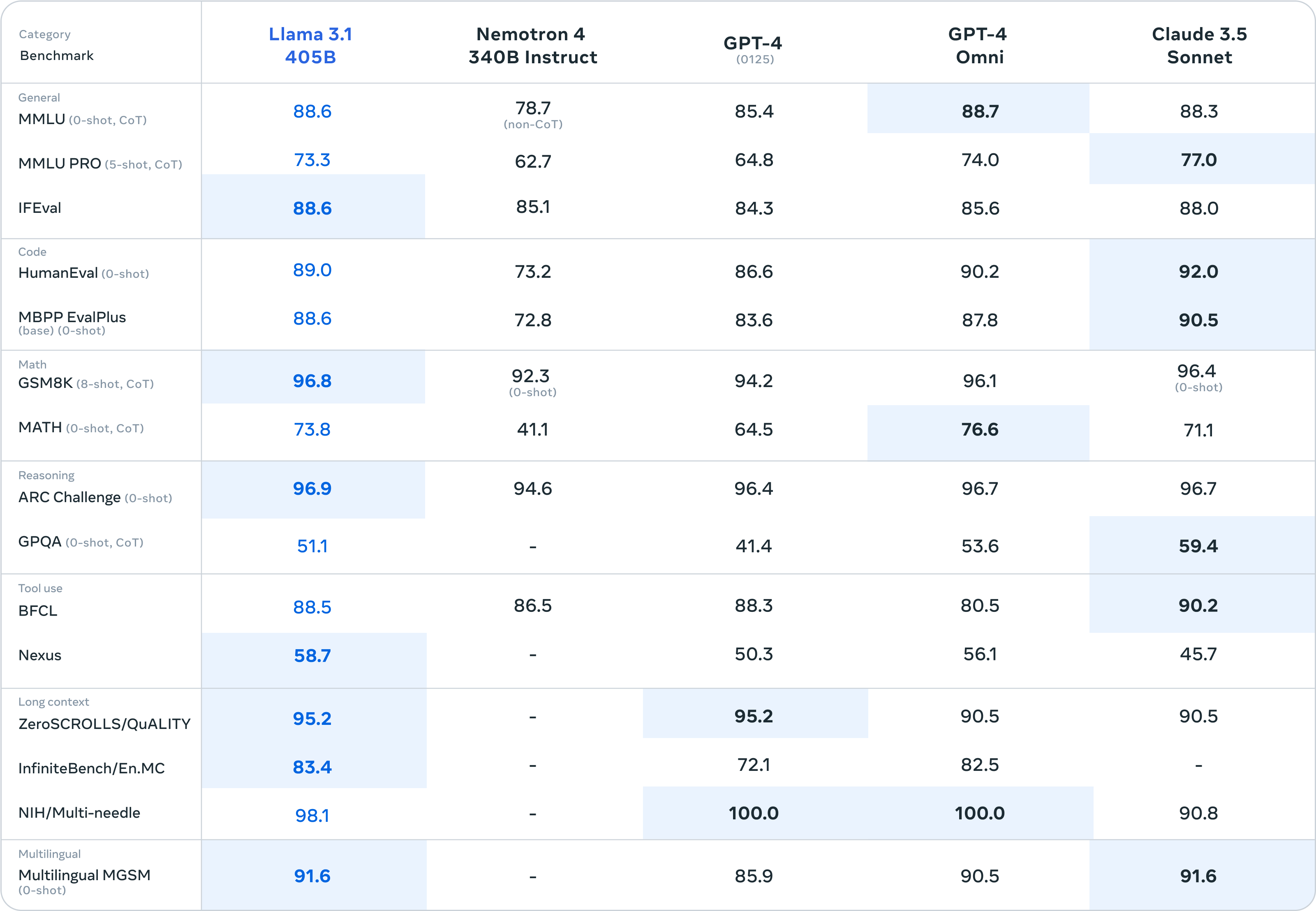
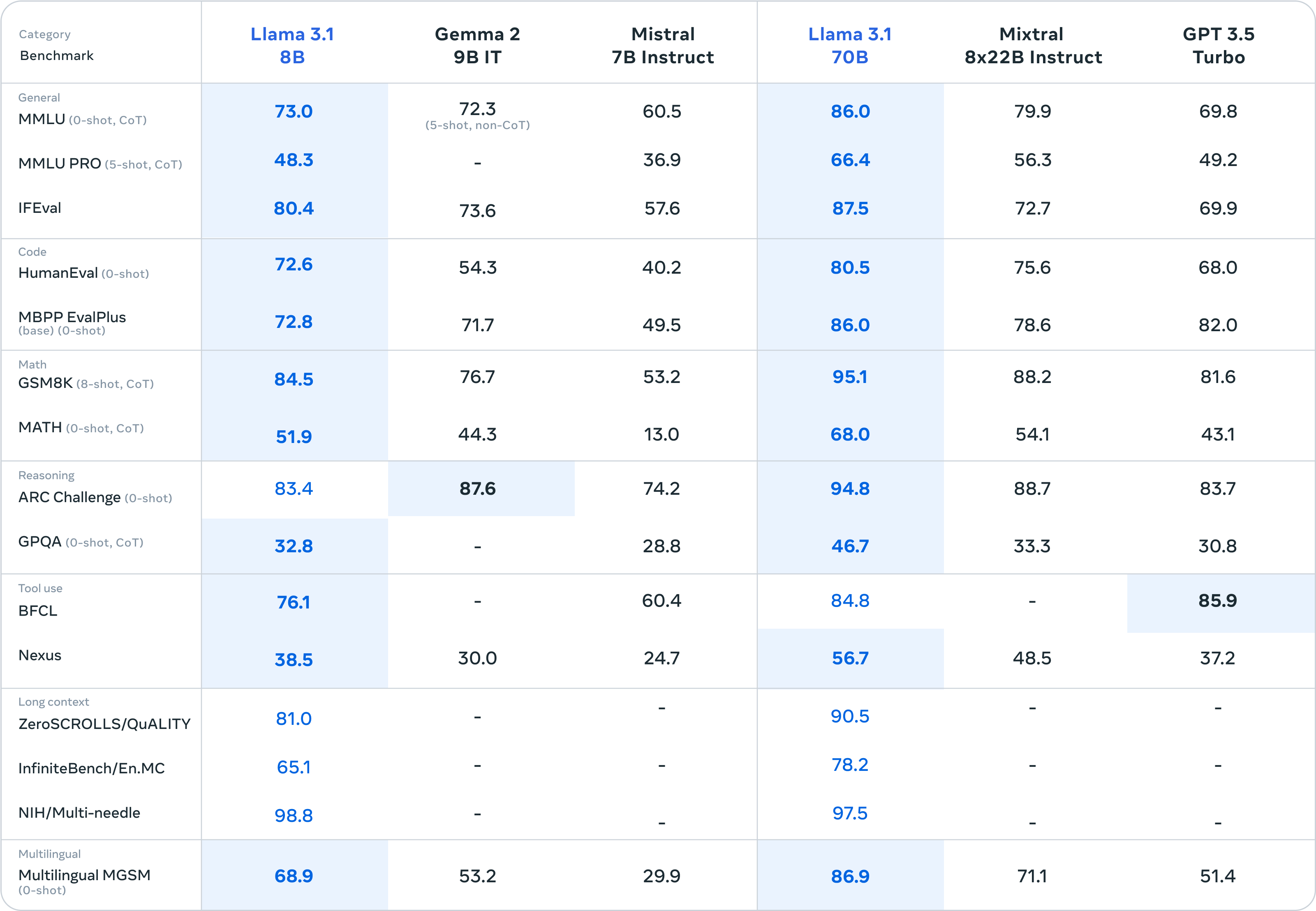
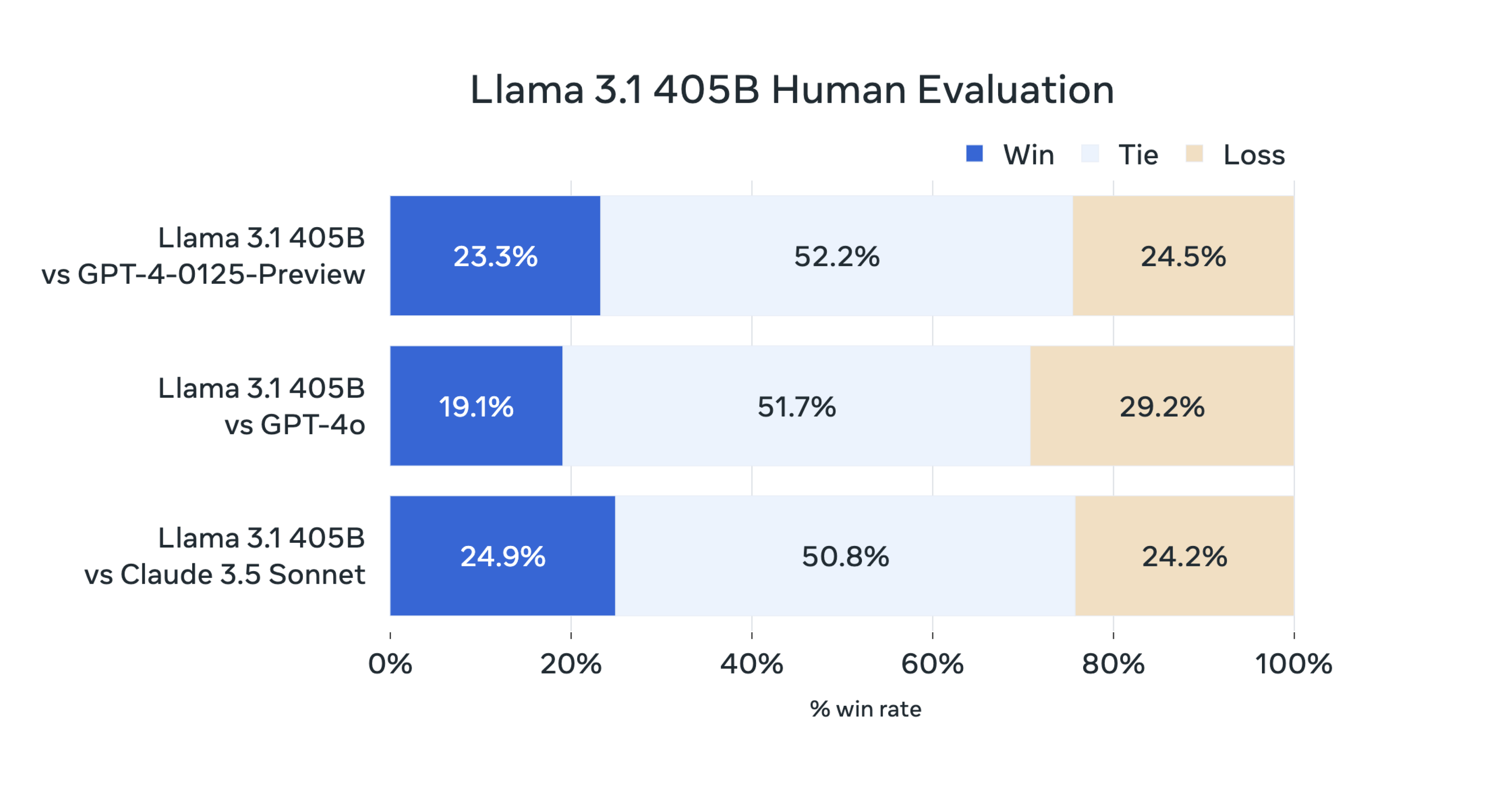
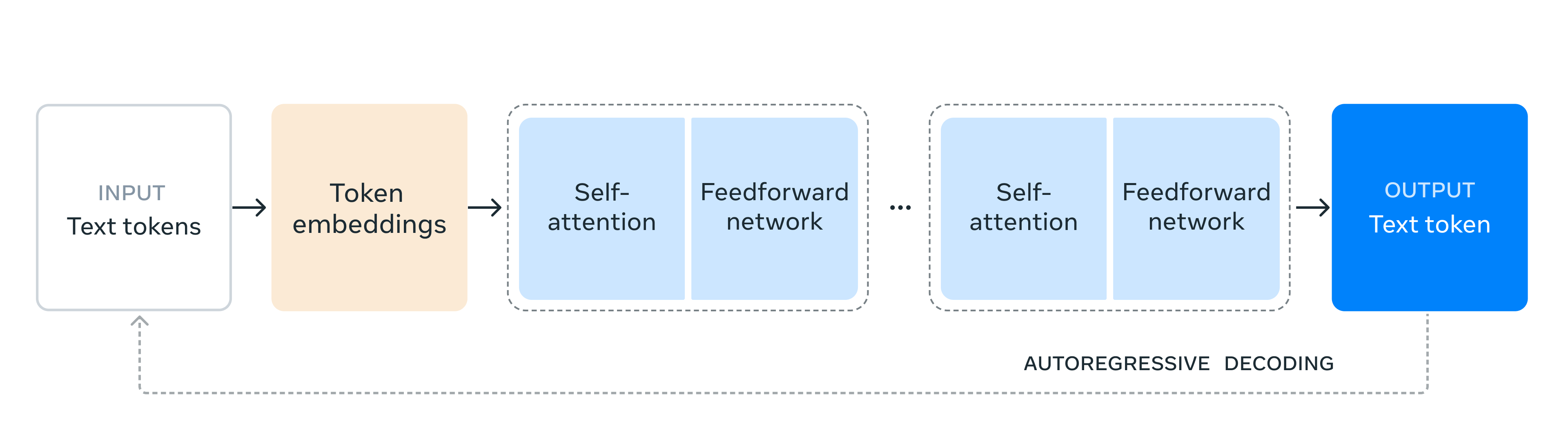
As our largest model yet, training Llama 3.1 405B on over 15 trillion tokens was a major challenge. To enable training runs at this scale and achieve the results we have in a reasonable amount of time, we significantly optimized our full training stack and pushed our model training to over 16 thousand H100 GPUs, making the 405B the first Llama model trained at this scale.
Official Meta News & Documentation
- https://llama.meta.com/
- https://ai.meta.com/blog/meta-llama-3-1/
- https://llama.meta.com/docs/overview
- https://llama.meta.com/llama-downloads/
- https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md
See also: The Llama 3 Herd of Models paper here:
HuggingFace Download Links
8B
Meta-Llama-3.1-8B
Meta-Llama-3.1-8B-Instruct
Llama-Guard-3-8B
Llama-Guard-3-8B-INT8
70B
Meta-Llama-3.1-70B
Meta-Llama-3.1-70B-Instruct
405B
Meta-Llama-3.1-405B-FP8
Meta-Llama-3.1-405B-Instruct-FP8
Meta-Llama-3.1-405B
Meta-Llama-3.1-405B-Instruct
Getting the models
You can download the models directly from Meta or one of our download partners: Hugging Face or Kaggle.
Alternatively, you can work with ecosystem partners to access the models through the services they provide. This approach can be especially useful if you want to work with the Llama 3.1 405B model.
Note: Llama 3.1 405B requires significant storage and computational resources, occupying approximately 750GB of disk storage space and necessitating two nodes on MP16 for inferencing.
Learn more at:
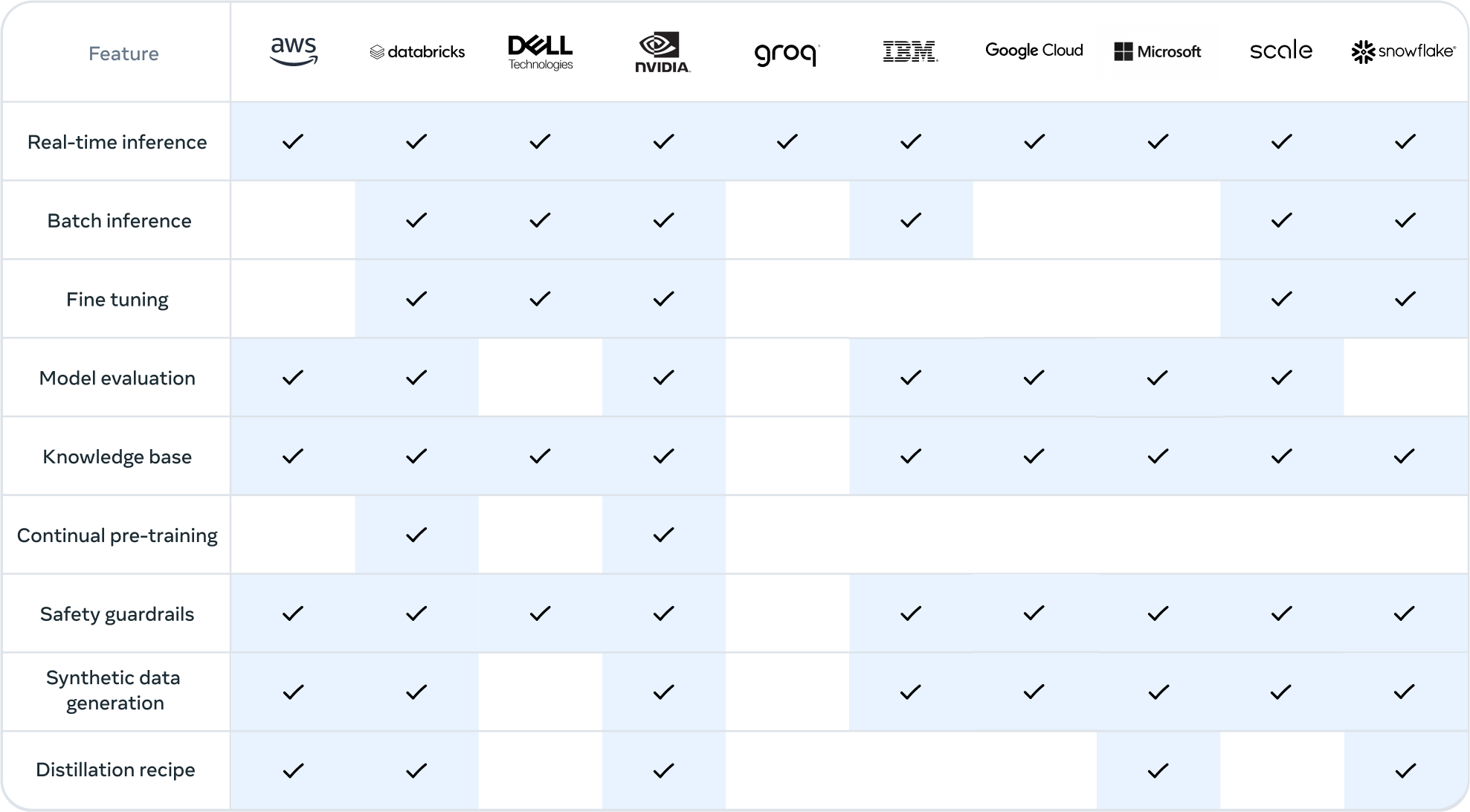
Running the models
Linux
Windows
Mac
Cloud
More guides and resources
How-to Fine-tune Llama 3.1 models
Quantizing Llama 3.1 models
Prompting Llama 3.1 models
Llama 3.1 recipes
YouTube media
Rowan Cheung - Mark Zuckerberg on Llama 3.1, Open Source, AI Agents, Safety, and more
Matthew Berman - BREAKING: LLaMA 405b is here! Open-source is now FRONTIER!
Wes Roth - Zuckerberg goes SCORCHED EARTH.... Llama 3.1 BREAKS the "AGI Industry"*
1littlecoder - How to DOWNLOAD Llama 3.1 LLMs
Bloomberg - Inside Mark Zuckerberg's AI Era | The Circuit