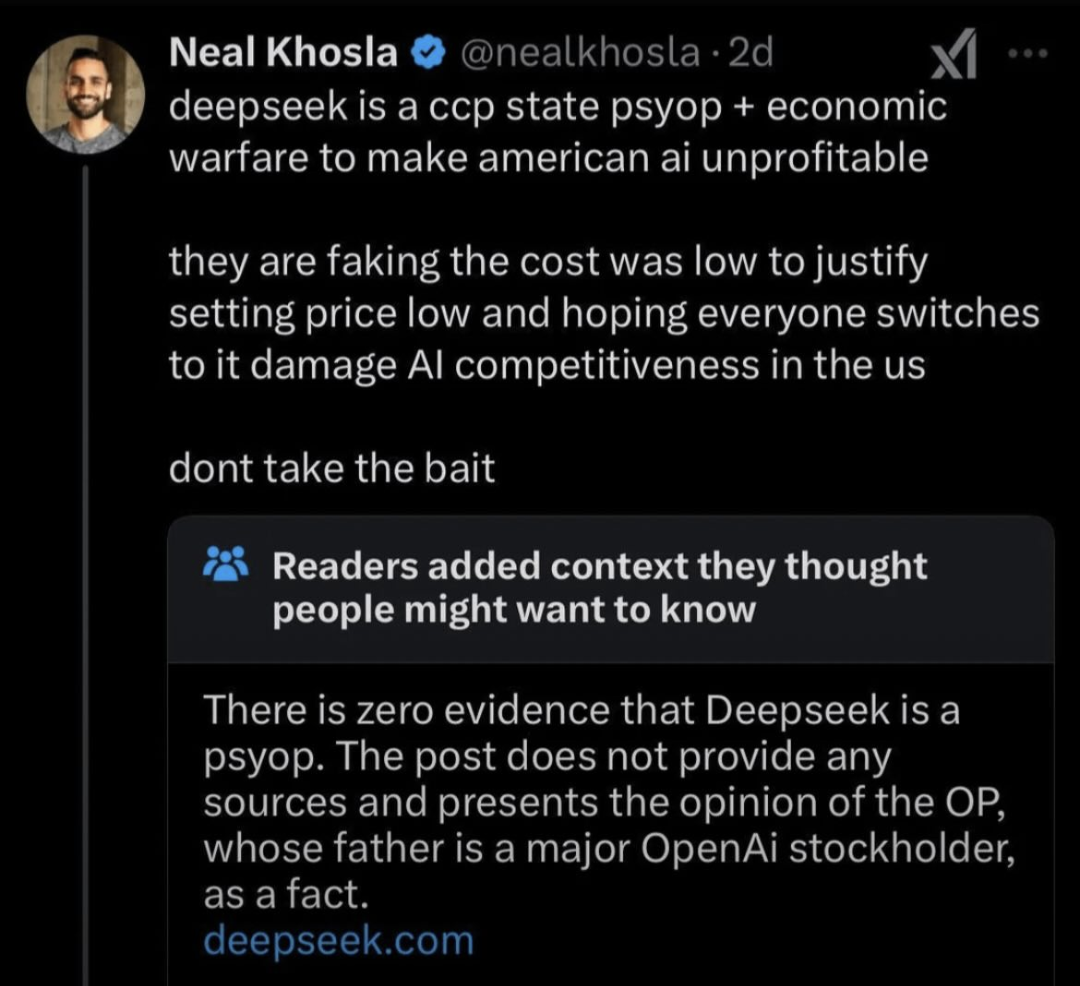
free market capitalist when a new competitor enters the market who happens to be foreign: noooooo this is economic warfare!!!!!
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
Related communities:
free market capitalist when a new competitor enters the market who happens to be foreign: noooooo this is economic warfare!!!!!
We literally are at the stage where when someone says: “this is a psyop” then that is the psyop. When someone says: “these drag queens are groomers” they are the groomers. When someone says: “the establishment wants to keep you stupid and poor” they are the establishment who want to keep you stupid and poor.
I mean it seems to do a lot of Chine-related censoring but it seems to otherwise be pretty good
I think the big question is how the model was trained. There's thought (though unproven afaik), that they may have gotten ahold of some of the backend training data from OpenAI and/or others. If so, they kinda cheated their way to their efficiency claims that are wrecking the market. But evidence is needed.
Imagine you're writing a dictionary of all words in the English language. If you're starting from scratch, the first and most-difficult step is finding all the words you need to define. You basically have to read everything ever written to look for more words, and 99.999% of what you'll actually be doing is finding the same words over and over and over, but you still have to look at everything. It's extremely inefficient.
What some people suspect is happening here is the AI equivalent of taking that dictionary that was just written, grabbing all the words, and changing the details of the language in the definitions. There may not be anything inherently wrong with that, but its "efficiency" comes from copying someone else's work.
Once again, that may be fine for use as a product, but saying it's a more efficient AI model is not entirely accurate. It's like paraphrasing a few articles based on research from the LHC and claiming that makes you a more efficient science contributor than CERN since you didn't have to build a supercollider to do your work.
China copying western tech is nothing new. That's literally how the elbowed their way up to the top as a world power. They copied everyones homework where they could and said, whatcha going to do about it?
If they are admittedly censoring, how can you tell what is censored and what’s not?
If you use the model it literally tells where it will not tell something to the user. Same as guardrails on any other LLM model on the market. Just different topics are censored.
So we are relying on the censor to tells us what they don’t censor?
AFAIK, and I am open to being corrected, the American models seem to mostly negate requests regarding current political discussions (I am not sure if this is still true even), but I don’t think they taboo other topics (besides violence, drug/explosives manufacturing, and harmful sexual conducts).
I wasn't under the impression American AI was profitable either. I thought it was held up by VC funding and over valued stock. I may be wrong though. Haven't done a deep dive on it.
Okay, I literally didn't even post the comment yet and did the most shallow of dives. Open AI is not profitable. https://www.cnbc.com/2024/09/27/openai-sees-5-billion-loss-this-year-on-3point7-billion-in-revenue.html
The CEO said on twitter that even their $200/month pro plan was losing money on every customer: https://techcrunch.com/2025/01/05/openai-is-losing-money-on-its-pricey-chatgpt-pro-plan-ceo-sam-altman-says/
I don't see how they would become profitable any time soon if their costs are that high. Maybe if they adapt the innovations of deepseek to their own model.
Interesting that all the propaganda and subversiveness is coming from the US, not China. Having the opposite of the desired effect.
So this guy is just going to pretend that all of these AI startups in thee US offering tokens at a fraction of what they should be in order to break-even (let alone make a profit) are not doing the exact same thing?
Every prompt everyone makes is subsidized by investors’ money. These companies do not make sense, they are speculative and everyone is hoping to get their own respective unicorn and cash out before the bill comes due.
My company grabbed 7200 tokens (min of footage) on Opus for like $400. Even if 90% of what it turns out for us is useless it’s still a steal. There is no way they are making money on this. It’s not sustainable. Either they need to lower the cost to generate their slop (which deep think could help guide!) or they need to charge 10x what they do. They’re doing the user acquisition strategy of social media and it’s absurd.