So what OOP is saying with their question is that the important attribute about that baby is that it is christian.
Meanwhile to a sane person, the important attribute about the baby is that it is a fucking baby flying through the fucking air!
For preserving the least toxic and most culturally relevant Tumblr heritage posts.
Image descriptions and plain text captions of written content are expected of all screenshots. Here are some image text extractors (I looked these up quick and will gladly take FOSS recommendations):
-web
-iOS
Please begin copied raw text posts (lacking a screenshot that makes it apparent it is from Tumblr) with:
# This has been reposted here to Lemmy as part of the "Curated Tumblr Project."
I made the icon using multiple creative commons svg resources, the banner is this.
So what OOP is saying with their question is that the important attribute about that baby is that it is christian.
Meanwhile to a sane person, the important attribute about the baby is that it is a fucking baby flying through the fucking air!
If its a budhist baby I'm putting that little shit out of the park. He will be reincarnated, my conscience is clear. /s
broke: i'm not gay but $20 is $20
woke: i'm not an atheist but millions of dollars is millions of dollars
I’d smash that baby out the park. One way ticket to see Jesus.
If it's a muslim baby it's totally OK to bat at it, of course.
Easy homerun.
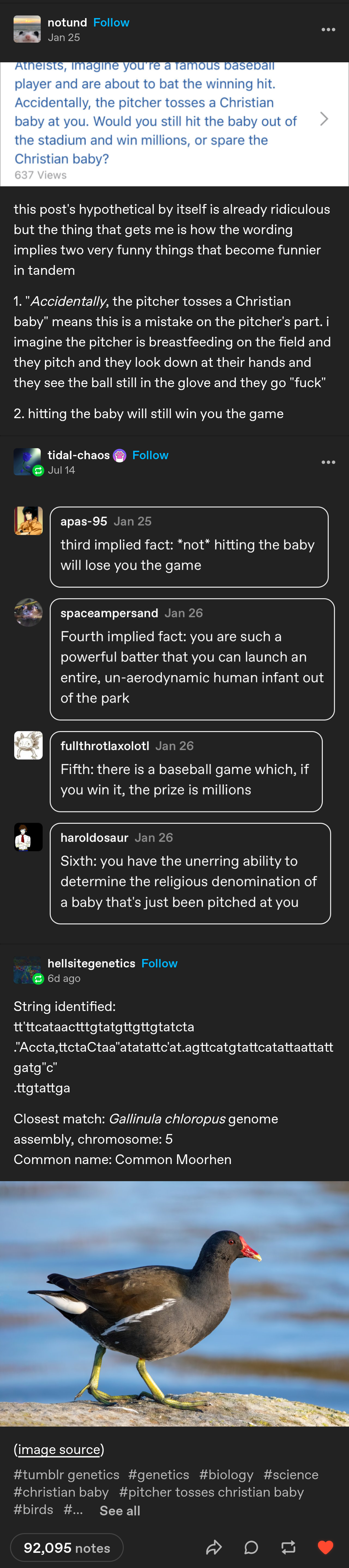
What is up with the bird at the end?
hellsitegenetics is a gimmick blog on tumblr that looks through popular posts on the website and tries to identify genetic sequences with in them and then post the creature that the genetic sequence corresponds to.
They're a bit like haiku bot, which scans posts to see if they're haikus and then formats the haiku and posts it, but i think hellsitegenetics is an actual person cuz they have talked about it in the past
A bot strips away all spaces and letters that aren't A, T, C or G, then treats the rest like a genetic sequence and checks it against some database.
Presumably, it runs through many terabytes of data for each comment, as the Gallinula chloropus alone has about 51 billion base pairs, or some 15 GiB. The Genome Ark DB, which has sequences of two common moorhens, contains over 1 PiB. I wonder if a bored sequencing lab employee just wrote it to give their database and computing servers something to do when there is no task running.
No, I won't download the genome and check how close the "closest match" is but statistically, 93 base pairs are expected to recur every 2^186^ bits or once per 10^40^ PiB. By evaluating the function (4-1)^m^ × mℂ93 ≥ 4^93^ ÷ (pebi × 8), one can expect the 93-base sequence to appear at least once in a 1 PiB database if m ≥ 32 mismatches or over ⅓ are allowed. Not great.
This assumes true randomness, which is not true of naturally occuring DNA nor letters in English text, but should be in the right ballpark.
The FAQ on the user's page says:
They are not a bot, just neurodivergent
They're using BLAST
ie, this
https://blast.ncbi.nlm.nih.gov/Blast.cgi
They did not code anything beyond a very simple regex function that strips down posts to a t c g, and then they copy paste it into the above website, then copy paste the output.
Hell, you can see they aren't even removing apostrophes and quotes, not even forcing it to all lower case or all upper case, removing spaces and line breaks...
... as a former database admin/dev/analyst, I was losing my fucking mind at the notion that someone with direct access to a genomics DB, would just hook it up to tumblr, via an automated bot, and spam the db with non work related requests, all on their own, when they can barely modify a string correctly.
Thank fucking god this is just using a publicly available, no doubt extremely low fidelity, watered down search via an API.
... You need literal, state of the art, absurdly expensive, power hungry, and secure supercomputers to be able to do genomic comparisons.
Probably one of the dumbest things you could do, quickest way to get fired, and then never be able to work in the field again, would be for a random genomics lab worker who does not know how to code to open up a whole bunch of security holes and cost god knows how much money (and damage if you write bad code) running frivolous bs searches in their state of the art genomics db... for a tumblr bot.
The genomes have likely been indexed to make finding results faster. Google doesn't search the entire internet when you make a query :P
I know that similar computational problems use indexing and vector-space representation but how would you build an index of TiBs of almost-random data that makes it faster to find the strictly closest match of an arbitrarily long sequence? I can think of some heuristics, such as bitmapping every occurrence of any 8-pair sequence across each kibibit in the list. A query search would then add the bitmaps of all 8-pair sequences within the query including ones with up to 2 errors, and using the resulting map to find "hotspots" to be checked with brute force. This will decrease the computation and storage access per query but drastically increase the storage size, which is already hard to manage.
However, efficient fuzzy string matching in giant datasets is an interesting problem that computer scientists must have encountered before. Can you find a good paper that works well with random, non-delimited data instead of just using the approach of word-based indices for human languages like Lucene and OpenFTS?
Yeah good point, not a trivial undertaking. I'm not an expert in that area but maybe elasticsearch or similar technology is able to find matches. Although I have no idea how that works under the hood
That's hilarious, but I needed the explanation too. Thanks!