All in all pretty decent sorry I attached a 35 min video but didn't wanna link to twitter and wanted to comment on this...pretty cool tho not a huge fan of mark but I prefer this over what the rest are doing...

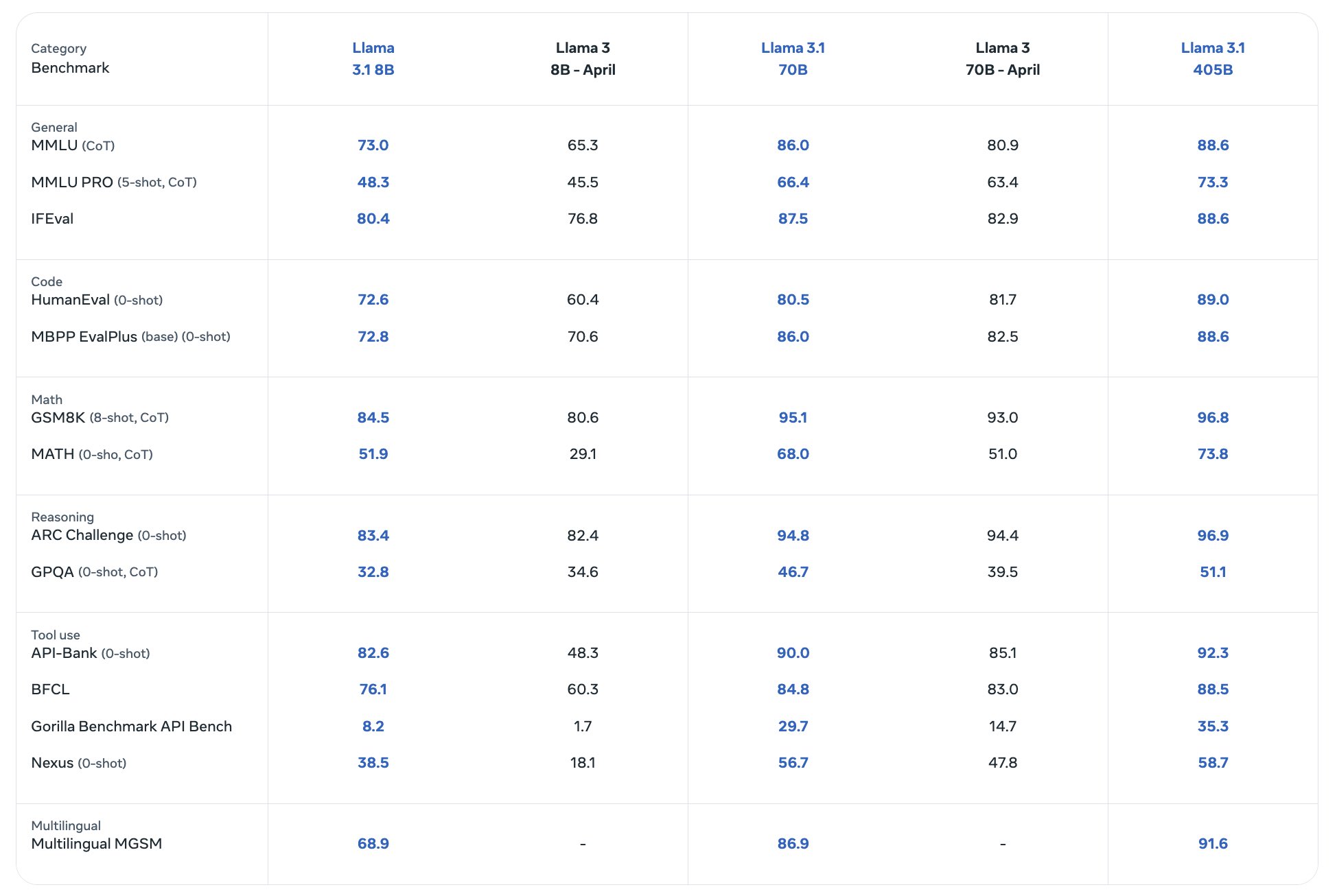
The open source AI model that you can fine-tune, distill and deploy anywhere. It is available in 8B, 70B and 405B versions.
Benchmarks