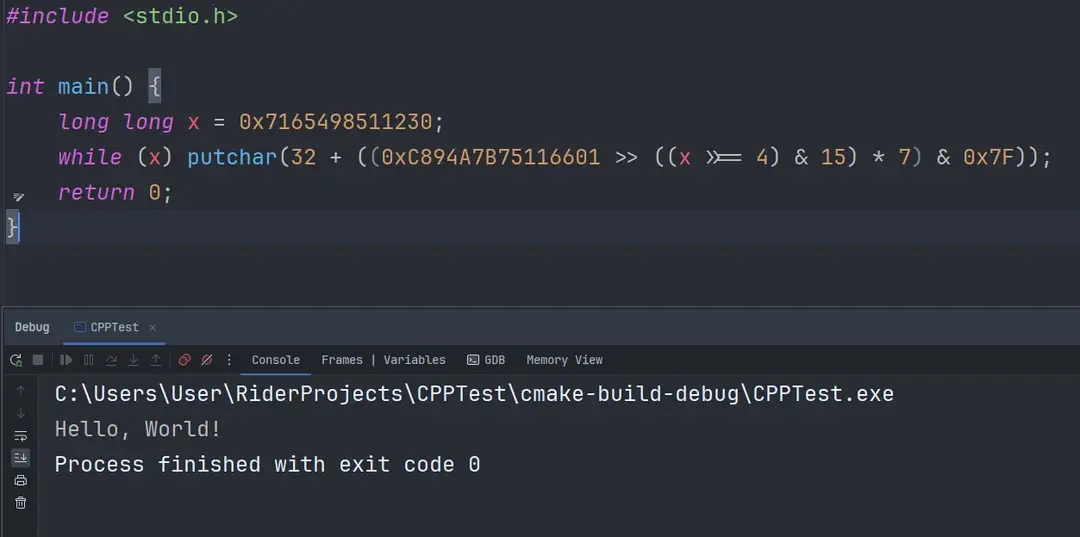
The best Hello World I saw used a random library. Because there's no true random without hardware, the author figured out the correct seed to write Hello World with "random" characters. I've used that to show junior devs that random in programming doesn't mean truly random.