Hello everyone, I have another exciting Mamba paper to share. This being an MoE implementation of the state space model.
For those unacquainted with Mamba, let me hit you with a double feature (take a detour checking out these papers/code if you don't know what Mamba is):
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- Official Mamba GitHub
- Example Implementation - Mamba-Chat
Now.. onto the MoE paper!
MoE-Mamba
Efficient Selective State Space Models with Mixture of Experts
Maciej Pióro, Kamil Ciebiera, Krystian Król, Jan Ludziejewski, Sebastian Jaszczur
State Space Models (SSMs) have become serious contenders in the field of sequential modeling, challenging the dominance of Transformers. At the same time, Mixture of Experts (MoE) has significantly improved Transformer-based LLMs, including recent state-of-the-art open-source models.
We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable, Transformer-like performance.
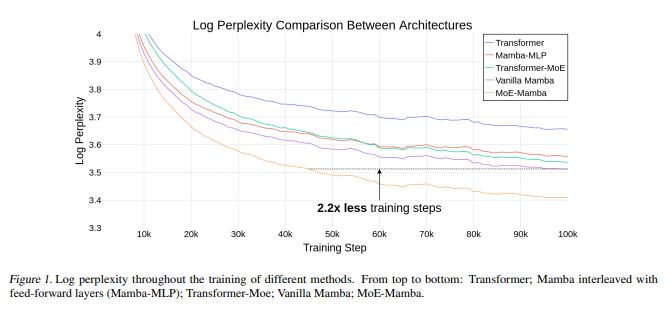
Our model, MoE-Mamba, outperforms both Mamba and Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer.
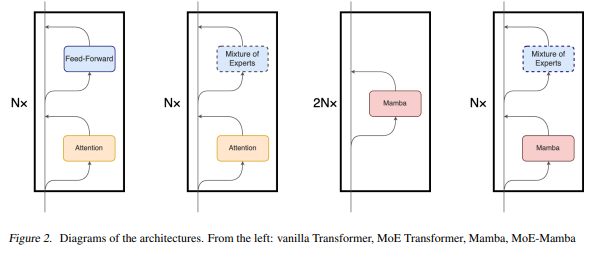
| Category | Hyperparameter | Value |
|---|---|---|
| Model | Total Blocks | 8 (16 in Mamba) |
| dmodel | 512 | |
| Feed-Forward | df f | 2048 (with Attention) or 1536 (with Mamba) |
| Mixture of Experts | dexpert | 2048 (with Attention) or 1536 (with Mamba) |
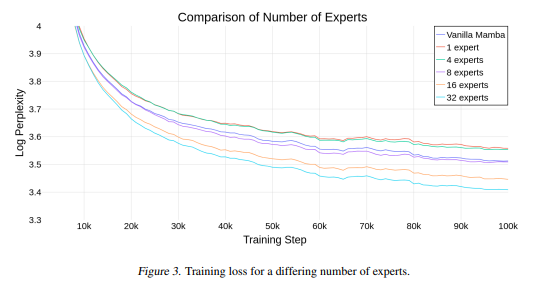
| Experts | 32 | |
| Attention | nheads | 8 |
| Training | Training Steps | 100k |
| Context Length | 256 | |
| Batch Size | 256 | |
| LR | 1e-3 | |
| LR Warmup | 1% steps | |
| Gradient Clipping | 0.5 |
MoE seems like the logical way to move forward with Mamba, at this point, I'm wondering could there anything else holding it back? Curious to see more tools and implementations compare against some of the other trending transformer-based LLM stacks.