{kind=link}
Before google existed I used https://www.metacrawler.com it appears to still be around. I have not used it in a long time, so I know nothing about it any longer.
this post was submitted on 19 Aug 2024
228 points (96.0% liked)
Technology
59331 readers
4672 users here now
This is a most excellent place for technology news and articles.
Our Rules
- Follow the lemmy.world rules.
- Only tech related content.
- Be excellent to each another!
- Mod approved content bots can post up to 10 articles per day.
- Threads asking for personal tech support may be deleted.
- Politics threads may be removed.
- No memes allowed as posts, OK to post as comments.
- Only approved bots from the list below, to ask if your bot can be added please contact us.
- Check for duplicates before posting, duplicates may be removed
Approved Bots
founded 1 year ago
MODERATORS
https://system1.com/ adtech company syndicating Bing and/or Google
This is a great question, in that it made me wonder why the Fediverse hasn't come up with a distributed search engine yet. I can see the general shape of a system, and it'd require some novel solutions to keep it scalable while still allowing reasonably complex queries. The biggest problems with search engines is that they're all scanning the entire internet and generating a huge percent of all internet traffic; they're all creating their own indexes, which is computationally expensive; their indexes are huge, which is space-expensive; and quality query results require a fair amount of computing resources.
A distributed search engine, with something like a DHT for the index, with partitioning and replication, and a moderation system to control bad actors and trojan nodes. DDG and SearX are sort of front ends for a system like this, except that they just hand off the queries to one (or two) of the big monolithic engines.
I thought Gigablast was a one-man company? Yet it had good search results and it was expansive.
load more comments
(1 replies)
We'd love to build a distributed search engine, but it would be too slow I think. When you send us a query we go and search 8 billion+ pages, and bring back the top 10, 20....up to 1,000 results. For a good service we need to do that in 200ms, and thus one needs to centralise the index. It took years, several iterations and our carefully designed algos & architecture to make something so fast. No doubt Google, Bing, Yandex & Baidu went through similar hoops. Maybe, I'm wrong and/or someone can make it work with our API.
load more comments
(3 replies)
load more comments
(2 replies)
Teclis - Includes search results from Marginalia, free to use at the moment. This search index has been in the past closed down due to abuse.
Kagi, whose creation Teclis is, is a paid search engine (metasearch engine to be more precise) also incorporates these search results in their normal searches. I warmly recommend giving Kagi a try, it's great, I've been enjoying it a lot.
--
Other options I can recommend; You could always try to host your own search engine if you have list of small-web sites in mind or don't mind spending some effort collecting such list. I personally host Yacy [github link] (and Searxng to interface with yacy and several other self-hosted indexes/search engines such as kiwix wiki's.). Indexing and crawling your own search results surprisingly is not resource heavy at all, and can be run on your personal machine in the background.
I tried running yacy for a while but it just ran for a bit less than a day then ran out of memory and crashed, over and over. Tried to figure out the problem, but it's niche enough that I couldn't get anywhere googling the issue.
This is a bit off-topic, but did you try to increase the JVM limits inside Yacy's administration panel?
Spoilering to hide wall of text related to this topic.
This setting located in /Performance_p.html-page for example gives the java runtime more memory. Same page also has other settings related to ram, such as setting how much memory Yacy must leave unused for the system. (These settings exist so people who run Yacy on their personal machines can have guaranteed resources for more important stuff)
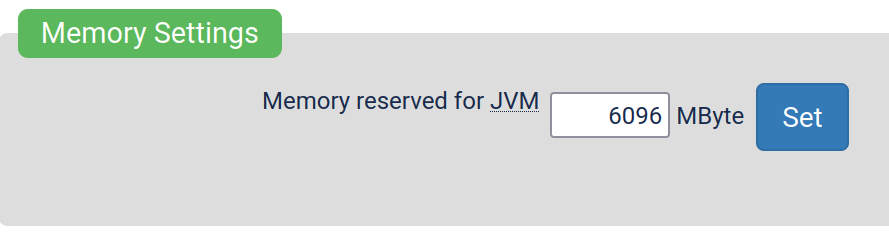
Other things that would reduce memory usage is to limit the concurrency of the crawler for example. There's quite a lot of tunable settings that can affect memory usage. Would recommend trying to hit up one of the Yacy forums is also good place to ask questions. The Matrix channel (and IRC) are a bit dead, but there are couple of people including myself there!
Also, theres new docs written by the community, they might help as well! https://yacy.net/docs/ https://yacy.net/operation/performance/
Yeah, I did try that. Basically, if I doubled the memory I allocated, I gave it half again longer before it crashed, but it still crashed, eventually.
It's no big deal, this was last year, I may try again one day. Loving Searxng though!
Not just a meta search engine though - they do have their own index as well.
https://help.kagi.com/kagi/search-details/search-sources.html
Yes, I mentioned Kagi because of the Teclis search index is hosted by them.
However, most of the search results in Kagi are aggregated from dedicated search engines. (such as, but not limited to: Yandex, Brave, Google, Bing, etc.)
load more comments
(1 replies)
You're looking for Kagi.com
Not only does it give better search results quality wise on "the big web" - you can select to search specific parts, like blogs.
Best part - it's completely ad and spam free. You pay for it with actual money instead of with your data.
Why not run an SearXNG instance and help everyone instead? Y'know, Kagi is pretty expensive and they are also getting into AI shit.
I've signed up for the €5 a month subscription at kagi and I've never used my whole quota.
Granted I expect it's overly expensive if you live in a developing country like Eritrea or the United States
5 euros a month for 300 searches. Definitely not worth it. I live in germany.
load more comments
(2 replies)
I'm hoping just as Proton do good free stuff using money I pay them (Visionary account) Kagi does/will do the same. The Internet as a whole needs to stop being ad-supported.
I refuse to believe Proton when they do advertisements lol. They also are being pretty suspicious with ignoring XMR support since years of people requesting it. If they ever even considered it a bit, their new shit Proton Wallet wouldn't allow you to store (or only store) bitcoin, which we all know has nothing that protects your privacy.
load more comments
(4 replies)
load more comments
(2 replies)
load more comments
(8 replies)
Replying under the top comment but this really applies to all of these, how do these search engines determine what counts as a personal site? For example I had procrastinated for years on finally spinning up a static, barren HTML blog. The infamous Lucidity AI post introduced me to Mataroa and I got over the hump and started writing. Would that get indexed? Etc
Does it just crawl through webrings?
I believe you have to submit your own website to this one for manual addition to its index
That is exactly what I needed; the subdomains are now in my bookmarks.
I'm intrigued. The search results are more akin to how they used to be 25 years ago on the internet that I loved
Https://Search.marginalia.nu is definitely something I'll be exploring going forward!
load more comments
(1 replies)
Don't know if this fits your criteria, but I've been using Gruble a lot recently. You can personalise the look and language in the settings, plus it's open source.
For info: That's (just) a SearXNG instance. That's a metasearch engine, getting results from Google etc and proxying and aggregating them for you.
load more comments
(1 replies)
load more comments
(1 replies)