Another day, another model.
Just one day after Meta released their new frontier models, Mistral AI surprised us with a new model, Mistral Large 2.
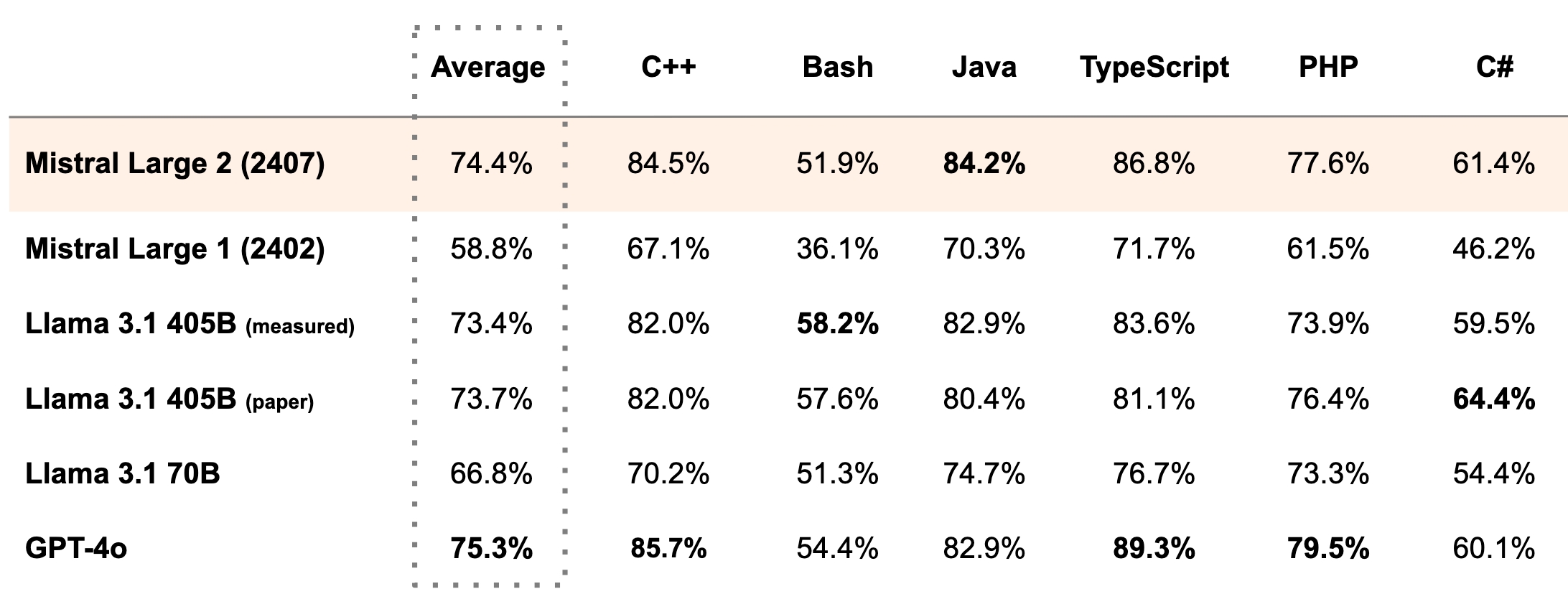
It's quite a big one with 123B parameters, so I'm not sure if I would be able to run it at all. However, based on their numbers, it seems to come close to GPT-4o. They claim to be on par with GPT-4o, Claude 3 Opus, and the fresh Llama 3 405B regarding coding related tasks.
It's multilingual, and from what they said in their blog post, it was trained on a large coding data set as well covering 80+ programming languages. They also claim that it is "trained to acknowledge when it cannot find solutions or does not have sufficient information to provide a confident answer"
On the licensing side, it's free for research and non-commercial applications, but you have to pay them for commercial use.
From what I've seen, it's definitely worth quantizing. I've used llama 3 8B (fp16) and llama 3 70B (q2_XS). The 70B version was way better, even with this quantization and it fits perfectly in 24 GB of VRAM. There's also this comparison showing the quantization option and their benchmark scores:
Source
To run this particular model though, you would need about 45GB of RAM just for the q2_K quant according to Ollama. I think I could run this with my GPU and offload the rest of the layers to the CPU, but the performance wouldn't be that great(e.g. less than 1 t/s).