this post was submitted on 06 Sep 2024
611 points (90.4% liked)
linuxmemes
21160 readers
1352 users here now
Hint: :q!
Sister communities:
Community rules (click to expand)
1. Follow the site-wide rules
- Instance-wide TOS: https://legal.lemmy.world/tos/
- Lemmy code of conduct: https://join-lemmy.org/docs/code_of_conduct.html
2. Be civil
- Understand the difference between a joke and an insult.
- Do not harrass or attack members of the community for any reason.
- Leave remarks of "peasantry" to the PCMR community. If you dislike an OS/service/application, attack the thing you dislike, not the individuals who use it. Some people may not have a choice.
- Bigotry will not be tolerated.
- These rules are somewhat loosened when the subject is a public figure. Still, do not attack their person or incite harrassment.
3. Post Linux-related content
- Including Unix and BSD.
- Non-Linux content is acceptable as long as it makes a reference to Linux. For example, the poorly made mockery of
sudo in Windows.
- No porn. Even if you watch it on a Linux machine.
4. No recent reposts
- Everybody uses Arch btw, can't quit Vim, and wants to interject for a moment. You can stop now.
Please report posts and comments that break these rules!
founded 1 year ago
MODERATORS
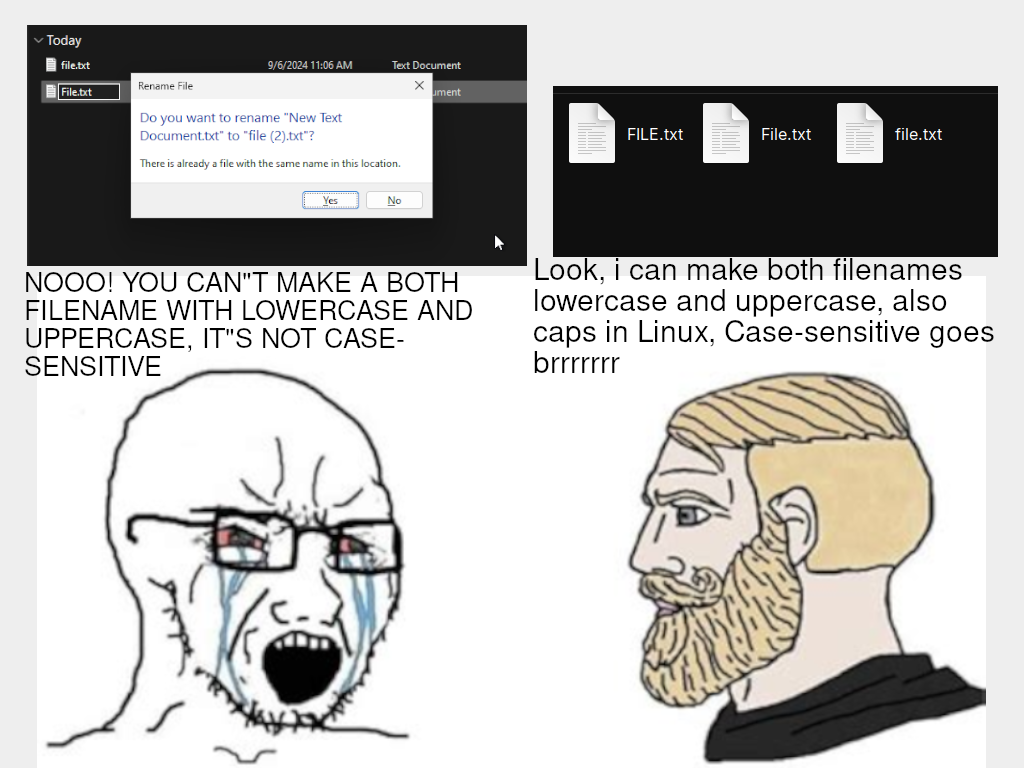
The reason, I suspect, is fundamentally because there's no relationship between the uppercase and lowercase characters unless someone goes out of their way to create it. That requires that the filesystem contain knowledge of the alphabet, which might work if all you wanted was to handle ASCII in American English, but isn't good for a system which needs to support the whole world.
In fact, the UNIX filesystem isn't ASCII. It's also not unicode. UNIX uses arbitrary byte strings, with special significance given to a very small number of bytes (just '/' and '\0', I think). That means people are free to label files in whatever way they like, and their terminals or other applications are free to render them in whatever way seems appropriate, without the filesystem having to understand unicode.
Adding case insensitivity would therefore actually be significant and unnecessary complexity to add to the filesystem drivers, and we'd probably take a big step backwards in support for other languages
You're basically arguing that a system shouldn't support user friendly things because that would add significant burden to the programmer.
The quintessential linux philosophy. Well done! I mean, what is language? Why have named code variables? This is just a random array of bytes!
No, I'm arguing that the extra complexity is something to avoid because it creates new attack surfaces, new opportunities for bugs, and is very unlikely to accurately deal with all of the edge cases.
Especially when you consider that the behaviour we have was established way before there even was a unicode standard which could have been applied, and when the alternative you want isn't unambiguously better than what it does now.
"What is language" is a far more insightful question than you clearly intended, because our collective best answer to that question right now is the unicode standard, and even that's not perfect. Making the very core of the filesystem have to deal with that is a can of worms which a competent engineer wouldn't open without very good reason, and at best I'm seeing a weak and subjective reason here.
Unicode case folding has been a solved problem for a long time. The Unicode standard has rules for which characters should be considered identical, and many libraries exist to handle it (you wouldn't ever code this yourself).